Solving (and Pwning) Flare-On level 10
The tenth and final challenge of Flare-On 11, "Catbert Ransomware" involves analysis of a ransomware decryption utility embedded within a custom UEFI firmware image.
If you've already solved this challenge, you might want to:
- Skip to Part 2, where I exploit a vulnerability in the C4TB VM
- Or checkout the bonus challenge at feedback.jpg.c4tb.chal.zip
Initial exploration
The distributed files consists of a "disk.img" (a FAT-12 disk image) and "bios.bin". After a bit of Google searching, we find that we can use QEMU to boot the system:
qemu-system-x86_64 -bios bios.bin -drive file=disk.img,format=raw -serial stdioWe are greeted with some cool ASCII art, a departure from the simplistic interfaces found in the prior challenges.
Most of the message is irrelevant to solving the challenge, except for the final section "Courtesy":
Ah, yes. I have bestowed upon you the privilege of decrypting four files, free of charge. Well, to be perfectly frank, you'll need to exercise your considerable intellect to decipher the first three images. The fourth exeutable, however, is my gift to you after figuring out the first three.
Consider it a token of my... esteem. You'll find the necessary decryption tool within this very shell. Now, if you'll excuse me, I have more pressing matters to attend to. Like, say, plotting the downfall of humanity.
This "decryption tool" can be found in the "help" menu:
C4tShell> help
...
decrypt_file - Decrypts a user chosen .c4tb file from a mounted storage, given a decryption key.
...To access the .c4tb files, we will need to access the filesystem stored in disk.img. This can be done by typing fs0:
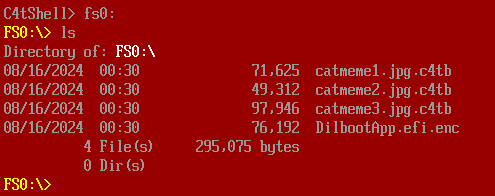
Unfortunately, running the command decrypt_file catmeme1.jpg.c4tb key just prints the message "Nope."
It's time to dig deeper.
Analysis
I used uefi_retool to extract the UEFI modules located within bios.bin. To figure out which module contains the decryption utility, let's grep for some strings we observed earlier:
$ rg -E utf-16le -l -a decrypt *
ShellLoading up the Shell module in IDA, we observe that the executable has been stripped, and there are almost no recognized functions.
However, lots of debugging strings are available, allowing the functions to be easily identified by referencing the open source EDK2 repository, which is the reference implementation of UEFI.
For example, consider the following assertion:
sub_12FD4(
"c:\\users\\dilbert\\edk2\\ShellPkg\\Library\\UefiShellLib\\UefiShellLib.c",
794LL,
"FileInfo != ((void *) 0)");We can see that line 794 in UefiShellLib.c is part of the ShellOpenFileByName function, and thus rename the function in IDA accordingly.
We can write a little IDAPython script to automate this process:
rename_funcs.py
import idaql # Wrapper over sark and ida_hexrays
import idc
import ida_funcs
import idaapi
EDK2_PATH = "~/edk2"
for call in list(idaql.get_calls_to("sub_12FD4")):
filename_arg = call.args[0]
if not filename_arg.concretized:
continue
linenum_arg = call.args[1]
if not linenum_arg.concretized:
continue
filename = idc.get_strlit_contents(filename_arg.value).decode()
if "DEBUG" in filename:
continue
filename = filename.replace('c:\\users\\dilbert\\edk2', EDK2_PATH).replace("\\", "/")
linenum = linenum_arg.value
with open(filename, "r") as f:
lines = [next(f) for _ in range(linenum)]
for i in range(1, linenum):
l = lines[-i]
if l.strip() and l[0].strip():
if l.strip()[-1] == "(":
name = l.replace("(", "").strip() # find line that looks like 'FuncNameHere ('
func = ida_funcs.get_func(call.ea).start_ea
idc.set_name(func, name, idaapi.SN_FORCE)
breakWith library functions identified, we can begin to figure out what is going on.
Searching for the string "Nope" from the failure message brings us to sub_31B14. This function, which I'll rename fail, prints the failure message. Searching for fail's callsite in turn brings us to sub_31BC4, which is the main handler for the decryption tool.
Notice that right before the call to fail is a bunch of array operations, followed by a call to sub_31274.
v14[4] = v9[2];
v14[12] = v9[4];
v14[11] = v9[6];
v14[19] = v9[8];
// ...
v14[46] = v9[26];
v14[54] = v9[28];
v14[53] = v9[30];
sub_31274();
if ( !qword_168ED0 )
{
LABEL_73:
fail();
return 2LL;
}Tossing the decompiled pseudocode of sub_31274 into any LLM of choice will reveal that it implements a stack based virtual machine. We'll come back to sub_31274 (which I'll rename check_key) later.
C4TB file format
By observing the memory access patterns in the pseudocode of main_handler, we can deduce that the c4tb file starts with the following header:
struct c4tb_header
{
int magic; // "C4TB" or 0x42543443
unsigned int data_size;
unsigned int program_offset;
unsigned int program_size;
};This is followed by data_size bytes of encrypted data. Finally, program_size bytes of C4TB stack VM instructions fill the space from program_offset to the end of the file.
Here's the decompilation of part of main_handler.
main_handler.c
file_contents = file_contents_1_1;
if ( !file_contents_1_1 )
return 9LL;
result = read_file(FileHandle, &a1, file_contents_1_1);
if ( result < 0 )
return result;
(gst->ConOut->SetAttribute)(gst->ConOut, 79LL);
print(-1, -1, L"Successfully read %d bytes from %s\r\n", a1, input_filename);
(gst->ConOut->SetAttribute)(gst->ConOut, 71LL);
state = malloc(32LL);
header_1 = &state->header;
if ( !state )
return 9LL;
file_contents_1 = file_contents;
magic = file_contents->header.magic;
state->header.magic = file_contents->header.magic;
if ( magic != 0x42543443 )
{
(gst->ConOut->SetAttribute)(gst->ConOut, 64LL);
print(-1, -1, L"Oh, you thought you could just waltz in here and decrypt ANY file, did you?\r\n");
print(-1, -1, L"Newsflash: Only .c4tb encrypted JPEGs are worthy of my decryption powers.\r\n");
(gst->ConOut->SetAttribute)(gst->ConOut, 71LL);
return 2LL;
}
data_size = file_contents_1->header.data_size;
header_1->data_size = data_size;
header_1->program_offset = file_contents_1->header.program_offset;
header_1->program_size = file_contents_1->header.program_size;
data = malloc(data_size);
v19 = state;
state->program = data;
if ( !data )
return 9LL;
CopyMem(data, file_contents->data, v19->header.data_size);
program_1 = malloc(state->header.program_size);
v21 = state;
state->data = program_1;
if ( !program_1 )
return 9LL;
CopyMem(program_1, file_contents + v21->header.program_offset, v21->header.program_size);
if ( StrLen(input_key) != 16 )
goto LABEL_73;
program_2 = malloc(state->header.program_size);
program_data = program_2;
if ( !program_2 )
return 9LL;
CopyMem(program_2, state->data, state->header.program_size);
input_key_1 = input_key;
program_data_1 = program_data;
program_data[5] = *input_key;
program_data_1[4] = input_key_1[2];
program_data_1[12] = input_key_1[4];
program_data_1[11] = input_key_1[6];
program_data_1[19] = input_key_1[8];
program_data_1[18] = input_key_1[10];
program_data_1[26] = input_key_1[12];
program_data_1[25] = input_key_1[14];
program_data_1[33] = input_key_1[16];
program_data_1[32] = input_key_1[18];
program_data_1[40] = input_key_1[20];
program_data_1[39] = input_key_1[22];
program_data_1[47] = input_key_1[24];
program_data_1[46] = input_key_1[26];
program_data_1[54] = input_key_1[28];
program_data_1[53] = input_key_1[30];
check_key();
if ( !qword_168ED0 )
{
LABEL_73:
fail();
return 2LL;
}Notice the check if ( StrLen(input_key) != 16 ) goto LABEL_73;. This tells us that the key must be 16 characters long.
The input_key is also copied to specific positions within the program_data. This is the only way user input enters the C4TB VM.
C4TB VM
Now that we've determined how data is formatted within a .c4tb file, let's turn our attention to the C4TB VM, which is the main focus of this challenge.
Fortunately for us, the C4TB architecture is simple and not unlike many other stack VM CTF challenges.
It is a 64-bit architecture, featuring an 8-byte wide stack, along with 8-byte addressable memory.
However, its instruction encoding is a little weird, and there are few areas that we need to pay attention to. For example, 2-byte constants are used, despite the 8-byte alignment of stack and memory. Additionally, immediates are encoded in big-endian, so the instruction
push 0xabcdwould be encoded 01 ab cd and not 01 cd ab.
Comparisons are performed through the lt, gt, eq instructions, which push the result (0 or 1) onto the stack. This is usually followed by the jnz instruction, which performs an absolute jump to the 2-byte jump destination if the value at the top of the stack is 1. The jz variant of this instruction is also available.
Most of the other instructions are fairly standard (arithmetic, binary operations, memory load/store).
In fact, this instruction set is so simple, and so standard, that LLMs like Claude can understand it pretty well.
After several rounds of prompting, a (partially working) Binary Ninja architecture plugin can be generated. This will decode the instructions, while telling Binary Ninja what the instructions actually do, in the form of Low Level IL.
Of course, it's not perfect, and here are some areas where I had to correct it:
- Some instructions are skipped, especially for instructions that perform similar functions. For example, the
storeandstorecinstructions differ only in the source of the data to be stored (popped from the stack vs encoded as an immediate). The LLM might decide to only implement one of them. This might in turn mess up the opcode assigned to subsequent instructions. - Conditional jumps. It's a little tricky to convey, in Binja LLIL at least, the fact that a stack pop operation occurs for every conditional jump, regardless of whether the branch is taken or not. The solution is to use a temporary register to store the result popped from the stack, and perform the comparison on this register instead. An example of this can be found in ethersplay, an EVM architecture plugin. In fact, as a stack based VM, C4TB shares much in common with EVM, so ethersplay is a good starting point for writing this plugin.
The architecture plugin can be found here:
c4tb.py
from binaryninja import *
class C4TB(Architecture):
name = "C4TB"
address_size = 8
default_int_size = 8
instr_alignment = 1
max_instr_length = 3
regs = {
"rsp": RegisterInfo("rsp", 8),
"ip": RegisterInfo("ip", 8)
}
stack_pointer = "rsp"
memory_base = 0x1337000
def get_instruction_info(self, data, addr):
result = InstructionInfo()
result.length = 1
opcode = data[0]
if opcode in [0xe, 0x0f, 0x10]: # Branch instructions
result.length = 3
target = struct.unpack(">H", data[1:3])[0]
if opcode in [0x10, 0xf]:
result.add_branch(BranchType.TrueBranch, target)
result.add_branch(BranchType.FalseBranch, addr + 3)
else:
result.add_branch(BranchType.UnconditionalBranch, target)
elif opcode in [0x01, 0x02, 0x03, 0x04, 0x0a, 0x10, 22]: # Instructions with 2-byte immediate
result.length = 3
return result
def get_instruction_text(self, data, addr):
opcode = data[0]
tokens = []
opcodes = {
0x00: "halt", 0x01: "push", 0x02: "loadc", 0x04: "storec",
0x05: "load", 0x06: "store", 0x07: "dup", 0x08: "pop",
0x09: "add", 0x0a: "addi", 0x0b: "sub", 0x0c: "div",
0x0d: "mul", 0x0e: "jmp", 0xf: "jnz",
0x10: "jz", 0x11: "eq", 0x12: "lt",
0x13: "le", 0x14: "gt", 0x15: "ge",
0x19: "return", 0x1a: "xor", 0x1b: "or", 0x1c: "and", 0x1d: "mod",
0x1e: "shl", 0x1f: "shr", 0x20: "rold", 0x21: "rord",
0x24: "rolb", 0x25: "rorb"
}
info = self.get_instruction_info(data, addr)
if opcode in opcodes:
tokens.append(InstructionTextToken(InstructionTextTokenType.InstructionToken, opcodes[opcode]))
if opcode in [0x01, 0x02, 0x03, 0x04, 0x0a, 0x10, 22]:
imm = struct.unpack(">H", data[1:3])[0]
tokens.append(InstructionTextToken(InstructionTextTokenType.OperandSeparatorToken, " "))
tokens.append(InstructionTextToken(InstructionTextTokenType.IntegerToken, hex(imm), imm))
elif opcode in [0xe, 0x0f, 0x10]:
target = struct.unpack(">H", data[1:3])[0]
tokens.append(InstructionTextToken(InstructionTextTokenType.OperandSeparatorToken, " "))
tokens.append(InstructionTextToken(InstructionTextTokenType.PossibleAddressToken, hex(target), target))
else:
tokens.append(InstructionTextToken(InstructionTextTokenType.TextToken, "invalid"))
return tokens, info.length
def calculate_address(self, il, index):
return il.add(8, il.const(8, self.memory_base),
il.mult(8,
index,
il.const(8, 8)))
def get_instruction_low_level_il(self, data, addr, il):
opcode = data[0]
info = self.get_instruction_info(data, addr)
if opcode == 0x00: # halt
expr = il.no_ret()
il.append(expr)
elif opcode == 0x01: # push
imm = struct.unpack(">H", data[1:3])[0]
expr = il.push(8, il.const(8, imm))
il.append(expr)
elif opcode == 0x02: # loadc
imm = struct.unpack(">H", data[1:3])[0]
expr = il.push(8, il.load(8, il.const(8, imm * 8 + self.memory_base)))
il.append(expr)
elif opcode == 0x04: # storec
imm = struct.unpack(">H", data[1:3])[0]
addr = il.pop(8) * 8 + self.memory_base
expr = il.store(8, il.const(8, imm), il.const_pointer(8, addr))
il.append(expr)
elif opcode == 0x05: # load
index = il.pop(8)
expr = il.push(8, il.load(8, self.calculate_address(il, index)))
il.append(expr)
elif opcode == 0x06: # store
value = il.pop(8)
index = il.pop(8)
il.append(il.store(8, self.calculate_address(il, index), value))
elif opcode == 0x09: # add
expr = il.push(8, il.add(8, il.pop(8), il.pop(8)))
il.append(expr)
elif opcode == 0x0b: # sub
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.sub(8, left, right))
il.append(expr)
elif opcode == 0x0c: # div
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.div_signed(8, left, right))
il.append(expr)
elif opcode == 0x0d: # mul
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.mult(8, left, right))
il.append(expr)
elif opcode == 0x0e: # jmp
target = struct.unpack(">H", data[1:3])[0]
t = il.get_label_for_address(self, target)
if t:
expr = il.goto(t)
else:
expr = il.jump(il.const(8, target))
il.append(expr)
elif opcode == 0x0f: # jnz
target = struct.unpack(">H", data[1:3])[0]
f_addr = addr + 3
il.append(il.set_reg(8, LLIL_TEMP(0), il.pop(8)))
condition = il.reg(8, LLIL_TEMP(0))
t = il.get_label_for_address(Architecture["C4TB"], target)
f = il.get_label_for_address(Architecture["C4TB"], f_addr)
target = il.const_pointer(8, target)
f_addr = il.const_pointer(8, f_addr)
if t and f:
il.append(il.if_expr(condition, t, f))
elif t:
f = LowLevelILLabel()
il.append(il.if_expr(condition, t, f))
il.mark_label(f)
il.append(il.jump(f_addr))
elif f:
t = LowLevelILLabel()
il.append(il.if_expr(condition, t, f))
il.mark_label(t)
il.append(il.jump(target))
else:
t = LowLevelILLabel()
f = LowLevelILLabel()
il.append(il.if_expr(condition, t, f))
il.mark_label(t)
il.append(il.jump(target))
il.mark_label(f)
il.append(il.jump(f_addr))
elif opcode == 0x10: # jz
target = struct.unpack(">H", data[1:3])[0]
f_addr = addr + 3
t = il.get_label_for_address(Architecture["C4TB"], target)
f = il.get_label_for_address(Architecture["C4TB"], f_addr)
target = il.const_pointer(8, target)
f_addr = il.const_pointer(8, f_addr)
il.append(il.set_reg(8, LLIL_TEMP(0), il.pop(8)))
condition = il.not_expr(8, il.reg(8, LLIL_TEMP(0)))
if t and f:
il.append(il.if_expr(condition, t, f))
elif t:
f = LowLevelILLabel()
il.append(il.if_expr(condition, t, f))
il.mark_label(f)
il.append(il.jump(f_addr))
elif f:
t = LowLevelILLabel()
il.append(il.if_expr(condition, t, f))
il.mark_label(t)
il.append(il.jump(target))
else:
t = LowLevelILLabel()
f = LowLevelILLabel()
il.append(il.if_expr(condition, t, f))
il.mark_label(t)
il.append(il.jump(target))
il.mark_label(f)
il.append(il.jump(f_addr))
elif opcode == 0x11: # eq
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.compare_equal(8, left, right))
il.append(expr)
elif opcode == 18: # lt
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.compare_signed_less_than(8, left, right))
il.append(expr)
elif opcode == 20: # gt
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.compare_signed_greater_than(8, left, right))
il.append(expr)
elif opcode == 19: # le
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.compare_signed_less_equal(8, left, right))
il.append(expr)
elif opcode == 21: # ge
imm = struct.unpack(">H", data[1:3])[0]
expr = il.push(8, il.compare_signed_greater_equal(8, il.pop(8), il.const(8, imm)))
il.append(expr)
elif opcode == 26: # xor
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.xor_expr(8, left, right))
il.append(expr)
elif opcode == 27: # or
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.or_expr(8, left, right))
il.append(expr)
elif opcode == 28: # and
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.and_expr(8, left, right))
il.append(expr)
elif opcode == 29: # mod
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.mod_unsigned(8, left, right))
il.append(expr)
elif opcode == 30: # shl
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.shift_left(8, left, right))
il.append(expr)
elif opcode == 31: # shr
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.logical_shift_right(8, left, right))
il.append(expr)
elif opcode == 32: # rold
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.rotate_left(4, left, right))
il.append(expr)
elif opcode == 33: # rord
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.rotate_right(4, left, right))
il.append(expr)
elif opcode == 36: # rolb
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.rotate_left(1, left, right))
il.append(expr)
elif opcode == 37: # rorb
right = il.pop(8)
left = il.pop(8)
expr = il.push(8, il.rotate_right(1, left, right))
il.append(expr)
elif opcode in [24,25]:
il.append(il.no_ret())
else:
expr = il.nop()
il.append(expr)
return info.length
class C4TBView(BinaryView):
name = "C4TB"
long_name = "Catbert Virtual Machine"
def __init__(self, data):
BinaryView.__init__(self, parent_view = data, file_metadata = data.file)
self.platform = Architecture['C4TB'].standalone_platform
@classmethod
def is_valid_for_data(self, data):
return data.read(0, 4) == b"C4TB"
def init(self):
program_offset = int.from_bytes(self.parent_view.read(8, 4), 'little')
program_size = int.from_bytes(self.parent_view.read(12, 4), 'little')
self.add_auto_segment(0, program_size, program_offset, program_size, SegmentFlag.SegmentReadable | SegmentFlag.SegmentExecutable)
self.add_auto_segment(0x1337000, 0x1000, 0, 0, SegmentFlag.SegmentReadable | SegmentFlag.SegmentWritable)
self.add_entry_point(0)
return True
def perform_get_address_size(self):
return 8
C4TB.register()
C4TBView.register()
print("C4TB architecture plugin loaded.")Flag checker
Stage 1
Anyway, after fixing the bugs, Binary Ninja can actually produce pretty good decompilation for C4TB. For example, here's the (significantly cleaned up) decompilation of the first program (catmeme1.jpg.c4tb):
part1.c
void sub_0() __noreturn
{
data[0] = 0xbbaa;
data[1] = 0xddcc
data[2] = 0xffee;
data[3] = 0xadde;
data[4] = 0xefbe;
data[5] = 0xfeca;
data[6] = 0xbeba;
data[7] = 0xcdab;
data[0xa] = 0x6144;
data[0xb] = 0x7534;
data[0xc] = 0x6962;
data[0xd] = 0x6c63;
data[0xe] = 0x3165;
data[0xf] = 0x6669;
data[0x10] = 0x6265;
data[0x11] = 0x6230;
data[8] = ((((data[3] << 0x30) | (data[2] << 0x20)) | (data[1] << 0x10)) | data[0]);
int64_t var_10_26 = (((data[7] << 0x30) | (data[6] << 0x20)) | (data[5] << 0x10));
data[9] = (var_10_26 | data[4]);
int64_t var_10_31 = (((data[0xd] << 0x30) | (data[0xc] << 0x20)) | (data[0xb] << 0x10));
data[0x12] = (var_10_31 | data[0xa]);
data[0x13] = ((((data[0x11] << 0x30) | (data[0x10] << 0x20)) | (data[0xf] << 0x10)) | data[0xe]);
index = 0;
still_running = 1;
num_correct = 0;
data_13370c8 = 0;
while (true)
{
if (still_running != 1)
break;
if (index < 8)
{
int64_t var_10_44 = data[8];
input_val = (var_10_44 >> (8 * index));
int64_t var_10_46 = data[0x12];
test_val = (var_10_46 >> (8 * index));
}
if (index > 7)
{
int64_t var_10_49 = data[9];
input_val = (var_10_49 >> (8 * index));
int64_t var_10_51 = data[0x13];
test_val = (var_10_51 >> (8 * index));
}
char input_val_1 = ((int8_t)input_val);
input_val = ((uint64_t)input_val_1);
char test_val_1 = ((int8_t)test_val);
test_val = ((uint64_t)test_val_1);
if (index == 2)
{
int64_t test_val_2 = test_val;
test_val = (ROLB(test_val_2, 4));
}
if (index == 9)
{
int64_t test_val_3 = test_val;
test_val = (RORB(test_val_3, 2));
}
if (index == 0xd)
{
int64_t test_val_4 = test_val;
test_val = (ROLB(test_val_4, 7));
}
if (index == 0xf)
{
int64_t test_val_5 = test_val;
test_val = (ROLB(test_val_5, 7));
}
if ((input_val == test_val) == 0)
{
still_running = 0;
}
if (input_val == test_val)
{
int64_t num_correct_1 = num_correct;
num_correct = (num_correct_1 + 1);
}
int64_t index_1 = index;
index = (index_1 + 1);
if (index > 0xf)
{
still_running = 0;
}
}
if (num_correct == 0x10)
{
data_13370c8 = 1;
}
int64_t var_8_58 = 0x19;
int64_t var_8_59 = data_13370c8;
/* no return */
}The first part of the program loads the input into memory. The 0xbbaa are just placeholders and will be replaced with the actual input bytes when the program is run. However, we must note that the byte order of every 2-byte chunk of the input is switched. For example, if the input starts with the bytes 12 34, then the first instruction will be data[0] = 0x3412.
Remember that the input is 16 bytes long, so the first 8 memory slots are used to store each 2 byte chunk. These chunks are then combined into two 8-byte values, located in data[8] and data[9]. A similar operation is performed for another set of hardcoded values, which will be used to determine if the input key is correct.
Moving on the main loop of the program, we can observe an iteration of the index from 0 to 15, where the corresponding byte of the input and the expected value is compared in each round. Most of the comparisons are straightforward, except for indices 2, 9, 13, and 15, where some bit rotations are performed on the test value before comparison.
>>> key = list(b"Da4ubicle1ifeb0b")
>>> key[2] = rol(key[2], 4, 8)
>>> key[9] = ror(key[9], 2, 8)
>>> key[13] = rol(key[13], 7, 8)
>>> key[15] = rol(key[15], 7, 8)
>>> bytes(key)
b'DaCubicleLife101'Now, we can use the key to decrypt the first .jpg:

Stage 2
Here's the key checker for the second stage. I've removed the part where input is loaded into data[8] and data[9], as it's the same as stage 1.
part2.c
void sub_0() __noreturn
{
// Setup omitted
index = 0;
still_running = 1;
num_correct = 0;
input_correct = 0;
data_13370e0 = 0x343fd;
data_13370e8 = 0x269ec3;
data_13370d8 = 0x80000000;
data_13370f0 = 0x1337;
while (true)
{
if (still_running != 1)
break;
// This part is the same too
if (index < 8)
{
int64_t var_10_47 = data[8];
input_val = (var_10_47 >> (8 * index));
int64_t var_10_49 = data[0x12];
test_val = (var_10_49 >> (8 * index));
}
if (index > 7)
{
int64_t var_10_52 = data[9];
input_val = (var_10_52 >> (8 * index));
int64_t var_10_54 = data[0x13];
test_val = (var_10_54 >> (8 * index));
}
char input_val_1 = ((int8_t)input_val);
input_val = ((uint64_t)input_val_1);
char test_val_1 = ((int8_t)test_val);
test_val = ((uint64_t)test_val_1);
// This is the actual math part
int64_t var_10_61 = ((data_13370e0 * data_13370f0) + data_13370e8);
data_13370f0 = (var_10_61 % data_13370d8);
data_13370d0 = data_13370f0;
int64_t var_10_65 = data_13370f0;
int64_t index_1 = index;
data_13370d0 = (var_10_65 >> (8 * (index_1 % 4)));
char var_10_67 = ((int8_t)data_13370d0);
data_13370f8 = ((uint64_t)var_10_67);
int64_t input_val_2 = input_val;
data_1337100 = (input_val_2 ^ data_13370f8);
if (data_1337100 == test_val == 0)
{
still_running = 0;
}
if (data_1337100 == test_val)
{
int64_t num_correct_1 = num_correct;
num_correct = (num_correct_1 + 1);
}
int64_t index_2 = index;
index = (index_2 + 1);
if (index > 0xf)
{
still_running = 0;
}
}
if (num_correct == 0x10)
{
input_correct = 1;
}
if (num_correct == 0x10 == 0)
{
input_correct = 0;
}
/* no return */
}This time, it seems that some arithmetic/binary shifting operations are used. From the decompiled pseudocode, we can easily extract the algorithm into Python:
>>> key = list(b"\x59\xa0\x4d\x6a\x23\xde\xc0\x24\xe2\x64\xb1\x59\x07\x72\x5c\x7f")
>>> a = 0x343fd
>>> b = 0x1337
>>> c = 0x269ec3
>>> for i in range(16):
b = ((a * b) + c) % 0x80000000
k = b >> (8*(i%4))
key[i] ^= k
key[i] %= 256
>>> bytes(key)
b'G3tDaJ0bD0neM4te'Thus, the second part of the flag is revealed:

PS: this algorithm is apparently Microsoft's implementation of rand seeded with 0x1337.
Stage 3
This stage is significantly longer than the others, and consists of 4 parts.
The first part checks the first 4 characters of the key:
data_13370f0 = 0xffffffff
index = 0;
num_correct = 0;
data_1337100 = 0;
accumulator_1 = 0x1505;
while (index < 4)
{
int64_t var_10_29 = data[8];
input_byte = (var_10_29 >> (8 * index));
char input_byte_1 = ((int8_t)input_byte);
input_byte = ((uint64_t)input_byte_1);
data_13370e8 = accumulator_1;
int64_t accumulator_1_1 = accumulator_1;
int64_t var_10_35 = ((accumulator_1_1 << 5) + data_13370e8);
accumulator_1 = (var_10_35 + input_byte);
int64_t index_1 = index;
index = (index_1 + 1);
}
int64_t accumulator_1_2 = accumulator_1;
accumulator_1 = (accumulator_1_2 & data_13370f0);
test_val_1 = 0x7c8df4cb;
if (test_val_1 == accumulator_1)
{
int64_t num_correct_1 = num_correct;
num_correct = (num_correct_1 + 1);
}Translated to Python:
def part1(key):
acc = 0x1505
for val in key[:4]:
acc = ((acc << 5) + acc) # This does acc = acc * 33
acc = (acc + val) & 0xffffffff
return acc == 0x7c8df4cbYou might recognize this as the djb2 hash algorithm. We can easily bruteforce through the pow(26*2+10, 4) combinations to find the matching hash:
import itertools
import string
charset = (string.ascii_letters + string.digits).encode()
for combi in itertools.product(charset, repeat=4):
if part1(bytes(combi)):
print(bytes(combi))Out of the possible outputs, VerY is most likely the correct answer.
Let's move on to part 2:
accumulator_2 = 0;
while (index < 8)
{
int64_t var_10_47 = data[8];
input_byte = (var_10_47 >> (8 * index));
char input_byte_2 = ((int8_t)input_byte);
input_byte = ((uint64_t)input_byte_2);
int64_t accumulator_2_1 = accumulator_2;
accumulator_2 = (RORD(accumulator_2_1, 0xd));
int64_t accumulator_2_2 = accumulator_2;
accumulator_2 = (accumulator_2_2 + input_byte);
int64_t index_2 = index;
index = (index_2 + 1);
}
accumulator_2 = (accumulator_2_3 & data_13370f0);
test_val_2 = 0x8b681d82;
if (test_val_2 == accumulator_2)
{
int64_t num_correct_2 = num_correct;
num_correct = (num_correct_2 + 1);
}This hash algorithm is relatively simple:
def part2(key):
acc = 0
for val in key[4:8]:
acc = ror(acc, 0xd, 32)
acc += val
return (acc & 0xffffffff) == 0x8b681d82Using the same bruteforce strategy, we can determine the correct input is DumB.
The third part checks the final 8 bytes of the key:
accumulator_3 = 1;
accumulator_4 = 0;
final_result = 0;
index = 0;
while (index < 8)
{
int64_t var_10_66 = data[9];
input_byte = (var_10_66 >> (8 * index));
char input_byte_3 = ((int8_t)input_byte);
input_byte = ((uint64_t)input_byte_3);
int64_t var_10_71 = (accumulator_3 + input_byte);
accumulator_3 = (var_10_71 % 0xfff1);
int64_t var_10_74 = (accumulator_4 + accumulator_3);
accumulator_4 = (var_10_74 % 0xfff1);
int64_t index_3 = index;
index = (index_3 + 1);
}
int64_t accumulator_4_1 = accumulator_4;
final_result = ((accumulator_4_1 << 0x10) | accumulator_3);
int64_t final_result_1 = final_result;
final_result = (final_result_1 & data_13370f0);
test_val_3 = 0xf910374;
if (test_val_3 == final_result)
{
int64_t num_correct_3 = num_correct;
num_correct = (num_correct_3 + 1);
}Translated to Python:
def part3(key):
a = 1
b = 0
for val in key[8:16]:
a = (a + val) % 0xfff1
b = (b + a) % 0xfff1
res = (b << 0x10) | a
return res == 0xf910374This function implements the Adler-32 hash algorithm. However, the 8 byte input is too large to bruteforce (in a short period of time anyway). Fortunately, Googling Adler-32 cracker brings up this page which tells us that the corresponding value is password.
Now, we can combine all 3 parts of the key into VerYDumBpassword, which allows us to decrypt the third .jpg:

PS: There's a fourth (redundant) part, which checks that the FNV1-32 hash of the entire key is 0x31f009d2.
Putting everything together
Once all 3 keys have been entered correctly, a fourth key is derived from the first 3, which is used to decrypt the DilbootApp.efi.enc file. Running the DilbootApp.efi file produces a your_mind.jpg.c4tb file. Fortunately, the password for this file is provided in the output of DilbootApp.efi: BrainNumbFromVm!.
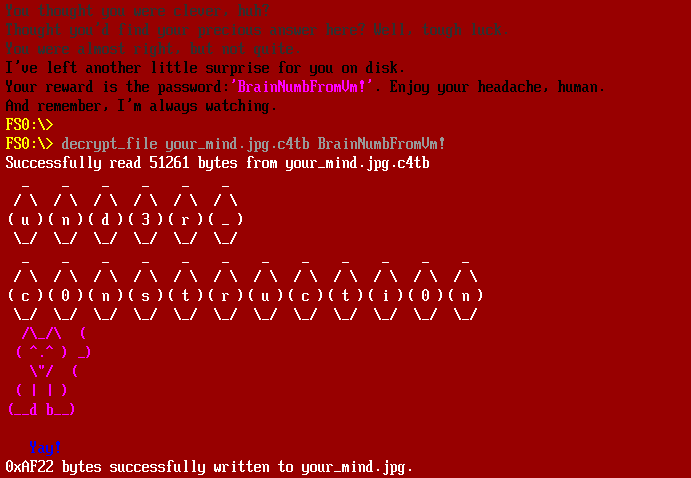
Decrypting your_mind.jpg.c4tb yields the final part of the flag: und3r_c0nstructi0n, and your_mind.jpg delivers the final @flare-on.com:

Putting everything together, the flag is [email protected].
Bonus challenge
Upon solving all 10 challenges, you are asked to fill out a feedback form to receive the prize, so I thought it would be cool if I encrypted my feedback using the C4TB VM.
You can download the bonus challenge here:
https://feedback.jpg.c4tb.chal.zip
Don't worry, it won't pwn your system 😉
Also don't forget to check out Part 2 where I pwn the C4TB VM!